
 As the (mostly) unidirectional tide of cultural influence flows from the U.S to the United Kingdom, the English mother tongue is becoming increasingly (and distressingly, I might add) populated by Americanisms: trash instead of rubbish, fries not chips, deplane instead of disembark, shopping cart instead of trolley, bangs rather than fringe, period instead of full stop. And there’s more: 24/7, heads-up, left-field, normalcy, a savings of, deliverable, the ask, winningest.
As the (mostly) unidirectional tide of cultural influence flows from the U.S to the United Kingdom, the English mother tongue is becoming increasingly (and distressingly, I might add) populated by Americanisms: trash instead of rubbish, fries not chips, deplane instead of disembark, shopping cart instead of trolley, bangs rather than fringe, period instead of full stop. And there’s more: 24/7, heads-up, left-field, normalcy, a savings of, deliverable, the ask, winningest.
All, might I say, utterly cringeworthy.
Yet, there may be a slight glimmer of hope, and all courtesy of the hipster generation. Hipsters, you see, crave an authentic, artisanal experience — think goat cheese and bespoke hats — that also seems to embrace language. So, in 2015, compared with a mere decade earlier, you’re more likely to hear some of the following words, which would normally be more attributable to an archaic, even Shakespearean, era:
perchance, mayhaps, parlor, amidst, amongst, whilst, unbeknownst, thou, thee, ere, hath
I’m all for it. My only hope now, is that these words will flow against the tide and into the U.S. to repair some of the previous linguistic deforestation. Methinks I’ll put some of these to immediate, good use.
From the Independent:
Hipsters are famous for their love of all things old-fashioned: 19th Century beards, pickle-making, Amish outerwear, naming their kids Clementine or Atticus. Now, they may be excavating archaic language, too.
As Chi Luu points out at JSTOR Daily — the blog of a database of academic journals, what could be more hipster than that? — old-timey words like bespoke, peruse, smitten and dapper appear to be creeping back into the lexicon.
This data comes from Google’s Ngram viewer, which charts the frequencies of words appearing in printed sources between 1800 and 2012.
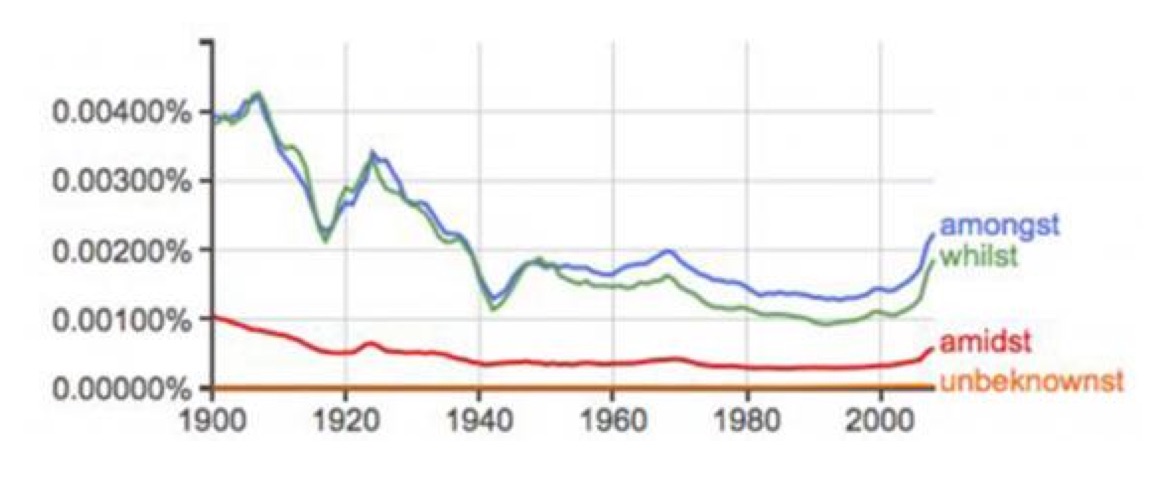
Google’s Ngram shows that lots of archaic words appear to be resurfacing — including gems like perchance, mayhaps and parlor.
The same trend is visible for words like amongst, amidst, whilst and unbeknownst, which are are archaic forms of among, amid, while and unknown.
Read the story in its entirety here.
Image courtesy of Google’s Ngram viewer / Independent.
