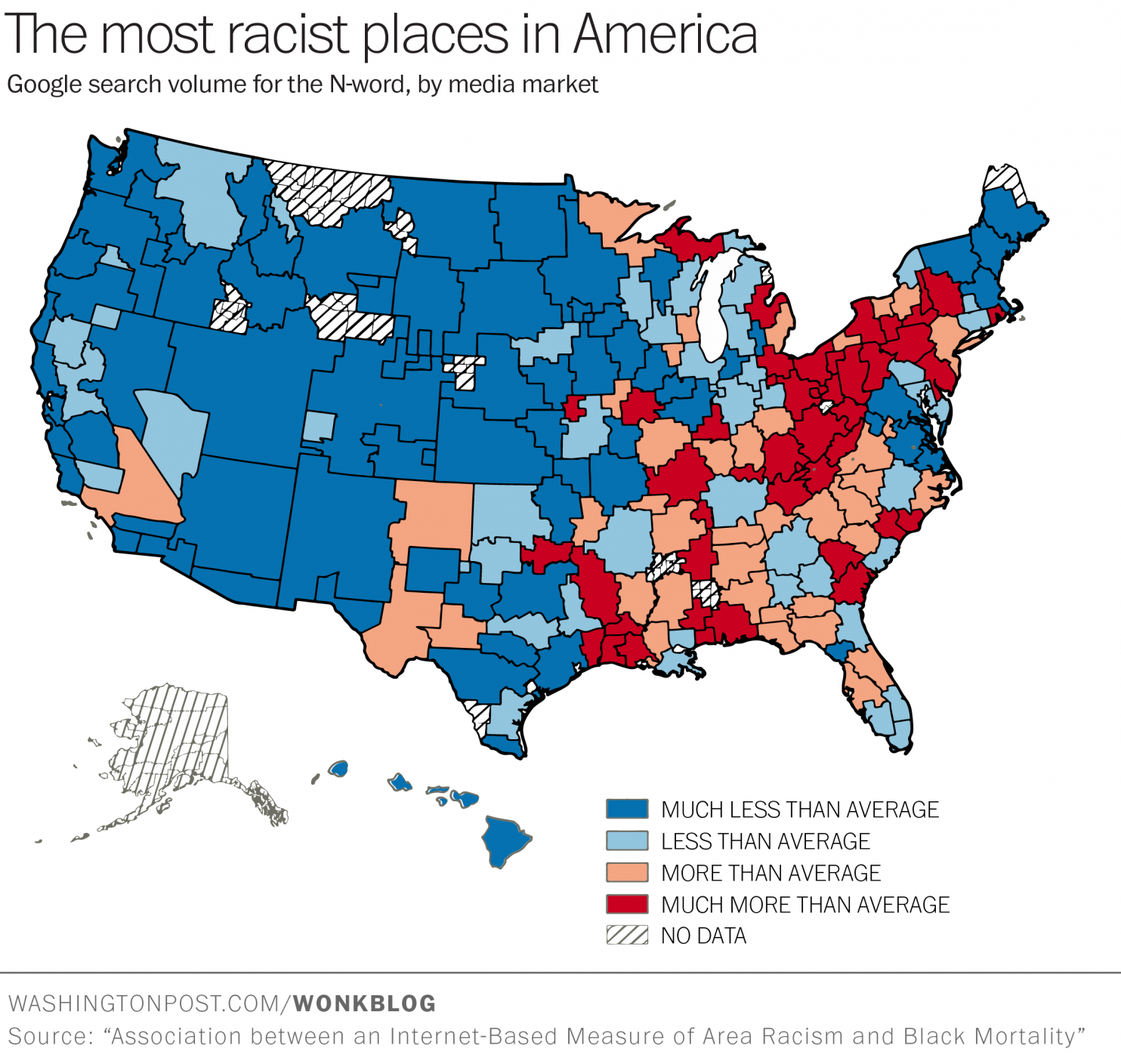
 It had never occurred to me, but it makes perfect sense: there’s a direct correlation between Muslim hates crimes and Muslim hate searches on Google. For that matter, there is probably a correlation between other types of hate speech and hate crimes — women, gays, lesbians, bosses, blacks, whites, bad drivers, religion X. But it is certainly the case that Muslims and the Islamic religion are taking the current brunt both online and in the real world.
It had never occurred to me, but it makes perfect sense: there’s a direct correlation between Muslim hates crimes and Muslim hate searches on Google. For that matter, there is probably a correlation between other types of hate speech and hate crimes — women, gays, lesbians, bosses, blacks, whites, bad drivers, religion X. But it is certainly the case that Muslims and the Islamic religion are taking the current brunt both online and in the real world.
Clearly, we have a long way to go in learning that entire populations are not to blame for the criminal acts of a few. However, back to the correlations.
Mining of Google search data shows indisputable relationships. As the researchers point out, “When Islamophobic searches are at their highest levels, such as during the controversy over the ‘ground zero mosque’ in 2010 or around the anniversary of 9/11, hate crimes tend to be at their highest levels, too.” Interestingly enough there are currently just over 50 daily searches for “I hate my boss” in the US. In November there were 120 searches per day for “I hate Muslims”.
So, here’s an idea. Let’s get Google to replace the “I’m Feeling Lucky” button on the search page (who uses that anyway) with “I’m Feeling Hateful”. This would make the search more productive for those needing to vent their hatred.
More from NYT:
HOURS after the massacre in San Bernardino, Calif., on Dec. 2, and minutes after the media first reported that at least one of the shooters had a Muslim-sounding name, a disturbing number of Californians had decided what they wanted to do with Muslims: kill them.
The top Google search in California with the word “Muslims” in it was “kill Muslims.” And the rest of America searched for the phrase “kill Muslims” with about the same frequency that they searched for “martini recipe,” “migraine symptoms” and “Cowboys roster.”
People often have vicious thoughts. Sometimes they share them on Google. Do these thoughts matter?
Yes. Using weekly data from 2004 to 2013, we found a direct correlation between anti-Muslim searches and anti-Muslim hate crimes.
We measured Islamophobic sentiment by using common Google searches that imply hateful attitudes toward Muslims. A search for “are all Muslims terrorists?” for example leaves little to the imagination about what the searcher really thinks. Searches for “I hate Muslims” are even clearer.
When Islamophobic searches are at their highest levels, such as during the controversy over the “ground zero mosque” in 2010 or around the anniversary of 9/11, hate crimes tend to be at their highest levels, too.
In 2014, according to the F.B.I., anti-Muslim hate crimes represented 16.3 percent of the total of 1,092 reported offenses. Anti-Semitism still led the way as a motive for hate crimes, at 58.2 percent.
Hate crimes may seem chaotic and unpredictable, a consequence of random neurons that happen to fire in the brains of a few angry young men. But we can explain some of the rise and fall of anti-Muslim hate crimes just based on what people are Googling about Muslims.
The frightening thing is this: If our model is right, Islamophobia and thus anti-Muslim hate crimes are currently higher than at any time since the immediate aftermath of the Sept. 11 attacks. Although it will take awhile for the F.B.I. to collect and analyze the data before we know whether anti-Muslim hate crimes are in fact rising spectacularly now, Islamophobic searches in the United States were 10 times higher the week after the Paris attacks than the week before. They have been elevated since then and rose again after the San Bernardino attack.
According to our model, when all the data is analyzed by the F.B.I., there will have been more than 200 anti-Muslim attacks in 2015, making it the worst year since 2001.
How can these Google searches track Islamophobia so well? Who searches for “I hate Muslims” anyway?
We often think of Google as a source from which we seek information directly, on topics like the weather, who won last night’s game or how to make apple pie. But sometimes we type our uncensored thoughts into Google, without much hope that Google will be able to help us. The search window can serve as a kind of confessional.
There are thousands of searches every year, for example, for “I hate my boss,” “people are annoying” and “I am drunk.” Google searches expressing moods, rather than looking for information, represent a tiny sample of everyone who is actually thinking those thoughts.
There are about 1,600 searches for “I hate my boss” every month in the United States. In a survey of American workers, half of the respondents
said that they had left a job because they hated their boss; there are about 150 million workers in America.
In November, there were about 3,600 searches in the United States for “I hate Muslims” and about 2,400 for “kill Muslims.” We suspect these Islamophobic searches represent a similarly tiny fraction of those who had the same thoughts but didn’t drop them into Google.
“If someone is willing to say ‘I hate them’ or ‘they disgust me,’ we know that those emotions are as good a predictor of behavior as actual intent,” said Susan Fiske, a social psychologist at Princeton, pointing to 50 years of psychology research on anti-black bias. “If people are making expressive searches about Muslims, it’s likely to be tied to anti-Muslim hate crime.”
Google searches seem to suffer from selection bias: Instead of asking a random sample of Americans how they feel, you just get information from those who are motivated to search. But this restriction may actually help search data predict hate crimes.
Read more here.
Image courtesy of Google Search.

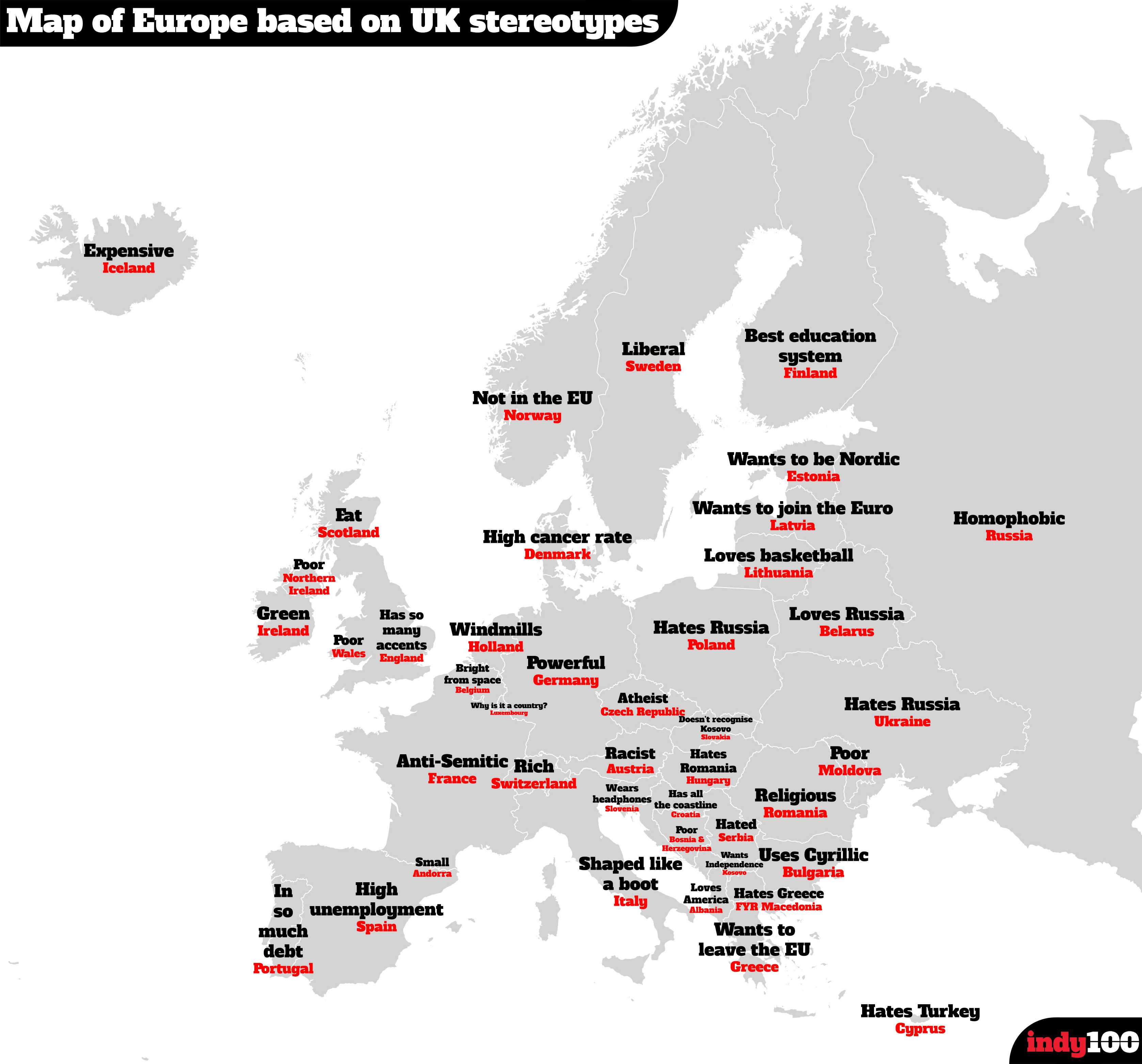 Hot on the heels of the map of US state stereotypes I am delighted to present a second one. This time it’s a map of Google searches in the UK for various nations across Europe. It was compiled by taking the most frequent result from Google’s autocomplete function. For instance, type in, “Why is Italy…”, and Google automatically fills in the most popular result with “Why is Italy shaped like a boot”.
Hot on the heels of the map of US state stereotypes I am delighted to present a second one. This time it’s a map of Google searches in the UK for various nations across Europe. It was compiled by taking the most frequent result from Google’s autocomplete function. For instance, type in, “Why is Italy…”, and Google automatically fills in the most popular result with “Why is Italy shaped like a boot”.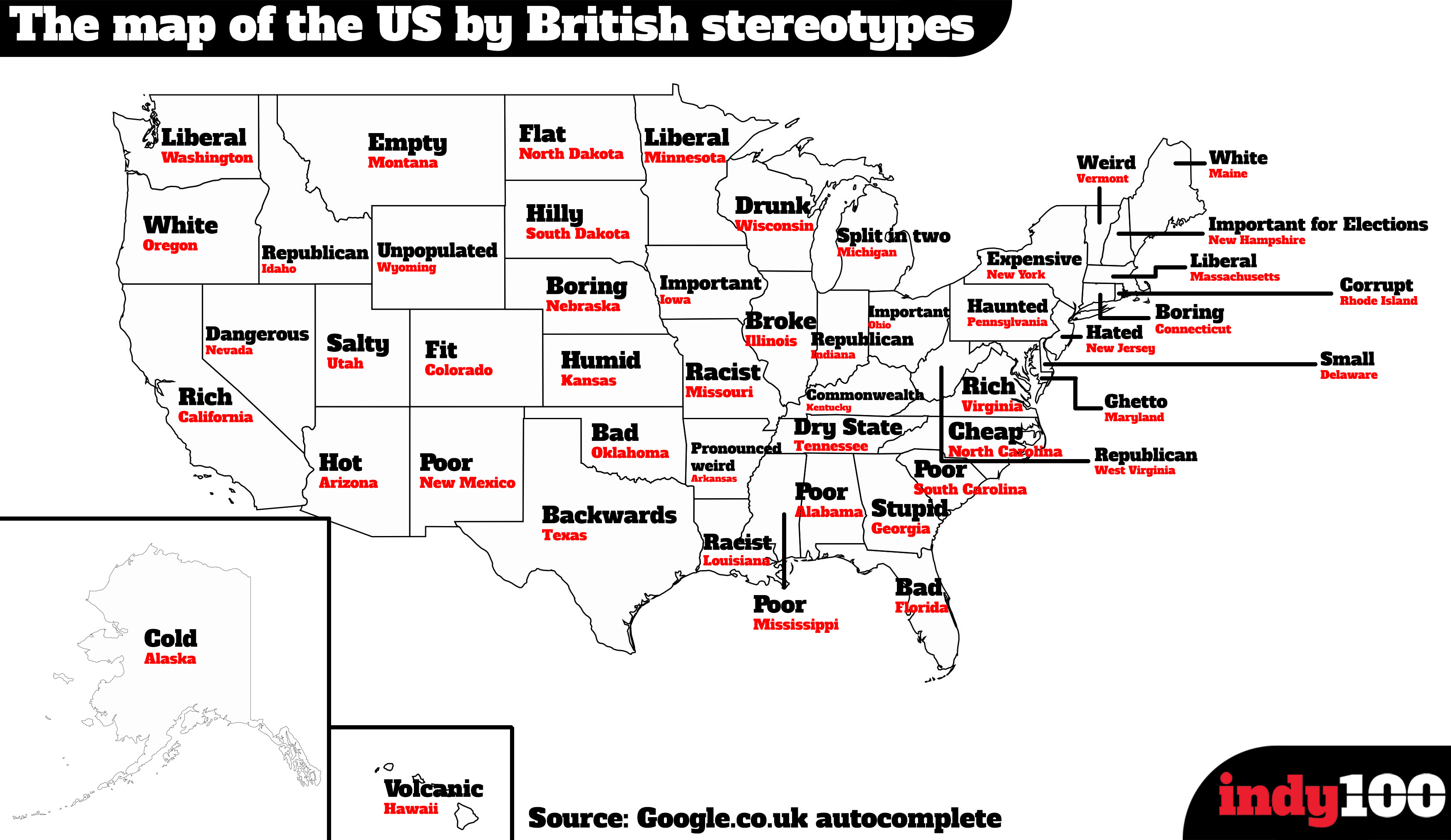





 Soon courtesy of Amazon, Google and other retail giants, and of course lubricated by the likes of the ubiquitous UPS and Fedex trucks, you may be able to dispense with the weekly or even daily trip to the grocery store. Amazon is expanding a trial of its same-day grocery delivery service, and others are following suit in select local and regional tests.
Soon courtesy of Amazon, Google and other retail giants, and of course lubricated by the likes of the ubiquitous UPS and Fedex trucks, you may be able to dispense with the weekly or even daily trip to the grocery store. Amazon is expanding a trial of its same-day grocery delivery service, and others are following suit in select local and regional tests. The collective IQ of Google, the company, inched up a few notches in January of 2013 when they hired
The collective IQ of Google, the company, inched up a few notches in January of 2013 when they hired  By all accounts serial entrepreneur, inventor and futurist Ray Kurzweil is Google’s most famous employee, eclipsing even co-founders Larry Page and Sergei Brin. As an inventor he can lay claim to some impressive firsts, such as the flatbed scanner, optical character recognition and the music synthesizer. As a futurist, for which he is now more recognized in the public consciousness, he ponders longevity, immortality and the human brain.
By all accounts serial entrepreneur, inventor and futurist Ray Kurzweil is Google’s most famous employee, eclipsing even co-founders Larry Page and Sergei Brin. As an inventor he can lay claim to some impressive firsts, such as the flatbed scanner, optical character recognition and the music synthesizer. As a futurist, for which he is now more recognized in the public consciousness, he ponders longevity, immortality and the human brain.




 Google has been variously praised and derided for its corporate manta, “Don’t Be Evil”. For those who like to believe that Google has good intentions recent events strain these assumptions. The company was found to have been snooping on and collecting data from personal Wi-Fi routers. Is this the case of a lone-wolf or a corporate strategy?
Google has been variously praised and derided for its corporate manta, “Don’t Be Evil”. For those who like to believe that Google has good intentions recent events strain these assumptions. The company was found to have been snooping on and collecting data from personal Wi-Fi routers. Is this the case of a lone-wolf or a corporate strategy?








 [div class=attrib]From The New York Times:[end-div]
[div class=attrib]From The New York Times:[end-div]